Still a DRAFT
All points I make are exclusively mine, not my employer. I mention vendor solutions but do not endorse any vendors. This white paper will be used in my NYU Summer 2017 class – Ultra Low Latency Architectures for Electronic Trading
Ted Hruzd
Introduction
Increasing number of electronic trading (ET) firms rely on market data architectures that are integral parts of single micro second (uS) Tick-to-Trade (T2T) processing times. Some architectures now also render T2T times of under 1 uS.
How do we define T2T?
T2T is the difference from T0 to T1 where T0 == time that a trading application receives market data quotes:
- directly from a Trading Venue (TV),
- or from the Securities Information Processor (SIP) that creates consolidated quotes (Consolidated Quote System (CQS) and Unlisted Quote Data Feed (UQDF)), from TV direct feeds,
And T1 == time the trading app is at point of sending an order to a TV
In CoLo environments, Multi-Layer switches with FPGA’s connect with trading venues and fan-out market data in 5 ns directly to FPGA devices for not only market data normalization but also all order and risk flow tasks leading to order generation (T2T). Other CoLo environments fan-out the market data to multi processor Intel Linux based servers, tuned to the max, and programmed utilizing deep vectors (Intel AVX-512) for increasing instructions per clock cycle and maximizing concurrent multi thread processing (Intel TBB), to the point of T2T.
All serious ULL trading apps strive for deterministic latencies in order to attain best trades even during high volume periods. FPGA processing results in deterministic latencies, processing at line speed. Hence, most ULL application rely at least in part on FPGA’s.
A major driver for deterministic ULL is due to significant enhancements to Big Data (BD) / Machine Learning (ML), resulting in alpha-seeking opportunities at times in uSecs. FPGA’s, GPU’s, high speed memory, and new robust ML API’s are a root cause. Aggressive firms increase their odds of catching alpha by architecting their infrastructure and application software for deterministic latencies, with the market data component key to not only single digit T2T but also for acting on timely market data confident of high % of successful fills. This new competitive landscape has lead to a new speed concept we refer to as Meta-Speed (information about speed, its relevance, and how to act on it – ex: Y/N for specific trades).
All major ET applications track their trading partner fill rates and latencies with OLAP, multi-dimensional metrics (time by second or less, symbol, quote-bid spreads, volume, price and volume volatility, etc ..), real time and historical. Decisions whether to trade per internal market data latencies and expected order ack & exec times of trading venues, are most critical to market makers, per their risky, ULL sensitive drive to generate revenue while establishing markets. Key themes and details behind these trends follow, including an appendix for reference and deeper research.
Tick to Trade (T2T) core components after trading application receives quote:
- Market data feed processing / normalization that leads to consolidated data (to distribute right away to subscribers) or direct feed data (to likewise distribute right away to subscribers and/or create multi level order books that subscribers can utilize in multiple ways)
- Concurrently (multi processing – using FPGA’s and/or Intel Cores) for:
- FIX (and non FIX protocol) message order processing that includes trading logic (ex: algo’s or simple direct orders), pre trade risk checks, identifying TV’s to send to, connecting to ‘exchange connectivity’ software & infrastructure, with order(s) ready to be routed over network to TV.
A leading T2T solution (under 1 uSec) is from Algo-Logic.
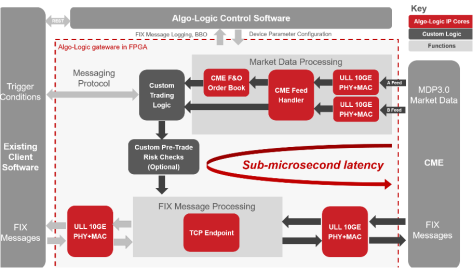
The details of a T2T under 1 micro second for CME market data / order flow : [1]
KEY THEMES
Meta-Speed
Speed1 is raw speed; Speed2 revolves around “meta-speed” (information about speed). An important aspect of Speed2 is deterministic speed. Speed2 is more important today than Speed1, with deterministic mkt data a key component.
Importance of Metrics
Metrics regarding speed (including mkt data speed, and especially tick to trade or “T2T”) are critical to maximizing fill rates and thus trading revenues:
- a large global investment bank has stated that every millisecond lost results in $100m per annum in lost opportunity.[1]
Alpha-Seeking
Alpha Trading Opportunities can be only few milliseconds long, and at times only in micro seconds, even nanoseconds now, due in part to Faster Real Time Market Data – Big Data Analytics
- Real Time Big Data (Machine Learning), some in Cloud, now can send more time sensitive alpha trading signals over high speed interconnects to Trading Apps
Pool for non ‘Low Latency’ Trading is Decreasing
Infrastructure and application development continue to improve, speed up, and become deterministic, for all Electronic Trading (ET) aspects, including mkt data. This includes recent Nasdaq implementation of SIP market data now (FIF November stats) at approximately 20 micro seconds, down from prior 350 micro seconds. At present, buy-side and exec brokers (sell-side), with ‘deterministic’ mkt data latencies (Exchg mkt data egress à networkàMktDataTickeràApp) of 1-2 milliseconds, may still be relevant, but less, with decreasing opportunities.
Key Questions
What does optimal access to high-speed / low-latency market data look like? Why is it important to achieve this?
A concise answer:
- They tend to be collocated (CoLo) with trading venues (TV). This will significantly decrease mkt data latency from TV’s to your infrastructure. Therefore Set up trading applications collocated (CoLo) with Trading venues for ULL market data (direct feeds) and order flow.
- A total FPGA based market data / order flow infrastructure allows for Tick to Trade latencies in single uSecs, even just under 1 uSec. Below is the flow:
- Exchg mkt data egress à CoLo networkàApp (can be 1 uSec or less)
- CoLo Managed Services that are used include Options-IT and Pico Trading.
- An innovative ULL network featuring a proprietary software defined network (SDN) solution, for connecting trading clients/applications to TV’s is available from Lucera. One can consider this a ULL extranet. Other extranets are available. Negotiate quality of service with them very meticulously.
- FPGA’s (in switches, appliances, NICs) are ideal for data transformation – hence a popular choice for feed handlers.. FPGA’s in appliances, switches, and NICs are increasingly being used for ingress and egress of market data, data normalization, order book builds, and analytics, as FPGA’s can be programmed for less market data jitter than multi threaded software in server CPU cores.
- Direct Feeds are used over Consolidated; build your own BBO (ex: UBBO or User BBO vs NBBO), as you will then receive direct feeds at same time consolidate feed vendors receive them. Exegy appliances calculate UBBO before it forwards NBBO; Exegy and all market data tickers receive NBBO via extra hop at SIP infrastructure that calculate NBBO (CTA and UTP) to subscribers.
- They use Multi Layer FPGA based L1-3 Switches. These are ideal in CoLo. A leading vendor is Metamako. Their Meta-Mux switches L2 aggregate market data and order flow data in 70 ns. Market data fan-outs are directed via L1 in 5 ns (ideal for subscribers who can then further normalize market data via FPGA’s). Multi layer switches (L1-3) can also significantly contribute to deterministic latencies, critical for competitive trading advantage.
- Some ULL infrastructures utilize appliances with integrated L1-3 switches, FPGA’s, and Intel cores. These appliances are available from Metamako and ExaBlaze as another alternative to consolidated market data, order flow processing, via multi thread FPGA and Intel core programming
- ULL architectures tend to reside on flatter networks with less hops; this includes a trend transitioning to a single tier network. Therefore, one strongly consider single tier network design, with Software Designed Network (SDN to optimize bandwidth and dynamically change and optimize routes for deterministic performance (may work well for market data analytics
- ULL architectures track latency metrics in real time, addressing Speed2 or Meta-Speed via appliances, such as Corvil. What is meta-speed?
- Corvil and Tabb coined ‘Speed 2’ or ‘meta-speed’. Briefly it references a decision point as to whether to send in an order or not. If the order is acting on a market data latency with high % of fill, then firm will tend to send it, else hold off. This is most critical to market making firms. We detail meta-speed further later.
- ULL ET firms track Historical and real time Big Data analytics / Machine Learning to address challenges to meta-speed.
- If FPGA solutions are not utilized then strict attention to following best practices must be adhered to:
- Kernel bypass must be implemented
- NICs must be segmented(separate for market data & order flow)
- Market data infrastructures must be performance optimized / tuned app (ex: multi threaded TREP – Hub, servers)
- Ex: Tune Reuters Elektron/TREP configuration with optimal #s threads for TREP hubs (ADH) and servers (ADS), maximizing market data throughput
- Conduct Capacity planning (all infrastructure, bandwidth, routers, switches, servers, middleware, client apps, caches); eliminate all MultiCast broadcast storms. This is great advice for all infrastructure
Following is a quote from a vendor that is not the fastest market data provider:
“whether you are running Alpha-seeking strategies or seeking best Ex for your agency business, consistently fast market data is a foundational requirement.”
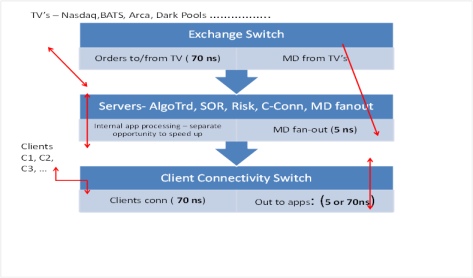
Below diagram depicts a CoLo ULL market data ingress/fan-out + ( market data normalization / order flow) solution. The latter can be fully FPGA based (ex: algo-logic CME infrastructyure) or part FPGA or Intel core solution optimized for multi threaded programming (TBB) and deep instruction vectors (AVX-512) to allow more instruction per clock cycle (versus prior AVX-256).
Metamako MetaMux switches with ( market data normalization / order flow) in the middle (diagram below): [2]
Advances in Kernel Bypass:
Total bypass of system and user space with TCP stack as part of FPGA based NIC for deterministic sub micro second network IO’s. Note the progression from 1st to 2nd to 3rd diagrams and comments by Enyx Laurent deBarry:
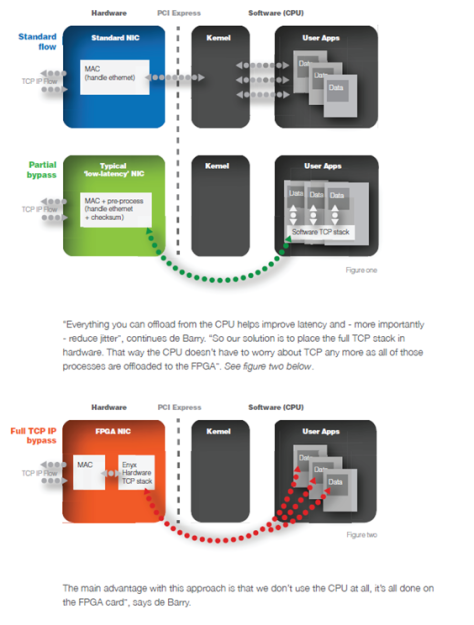
Who are some of the leading vendors in this space ?
- Metamako
- Intel/Altera
- Algo-Logic
- NovaSparks
- Exegy
- SolarFlare
- ExaBlaze
- Enyx
- Mellanox
- FixNetics
- Arista
- Cisco
- Corvil
- Options-IT
- PicoTrading
- Plexxi Networks
Why is it important to maintain deterministic latencies, with mkt data a key component?
End 2 end connectivity, infrastructure, and the software must be architected for not only speed (ex: tick-2-trade or T2T times in micro, not milliseconds) but also deterministic speed. Deterministic speed is important because serious traders, for over a decade, have tracked latencies and fill rates with their trading partners. Technology is now available to largely eliminate peaks in latencies at times of market data spikes. Serious traders know the sell-side, execution brokers, dark pools, and trading venues that exhibit deterministic speed (and low latencies). They trade with them especially in volatile times. The best opportunities for most competent algo traders are to take advantage of volatile and high volume periods. Their trading signals have a short life, often in micro seconds. They know where to route orders. The most successful buy side traders will also route to the fastest and most deterministic sell side firms. Sell side will optimize their dark pools for deterministic speed and know when to send to other dark pools and lit exchanges, in large part to very significant advances in Big data analytics.
What are the factors that disrupt this optimal scenario?
Optimal infrastructure may be full or partial FPGA, layer 1 switch, and CoLo based. Those that are not, can still be relevant for speed (T2T in microseconds) and deterministic latencies if they follow know best practices that will reduce market data latency jitter. If one does not follow these best practices, then that will disrupt not only an optimal scenario, but their market share / business. These include:
- Never configure market data and order flow on the same network interface (NIC). A spike in one will negatively impact latencies of the other.
- Configure kernel bypass on all of your NICs. Several vendors offer out of the box kernel bypass for much lower I/O latencies – to 1 microsecond from 12 or more microseconds.
- One can attain additional NIC speed with Optimized APIs for publishers and subscribers of the NIC data. The fastest and most deterministic kernel bypass devices are FPGA based. Full TCP stacks can be implemented in FPGA cards in NICs; hence not only is system space bypassed but user space too in CPU cores, allowing much more in CPU core processing power. Kernel bypass has been successful for over 6 years. Upgrade immediately if you do not use kernel bypass
- Optimize your Linux server kernels – ex RH 7.2 profile “network latency” priorities speed over bandwidth energy savings. Speed up your CPU core processing, decrease your jitter, with this profile [3]
- Continuously monitor and update metrics, your KPI’s such as latencies and fill rates per trading partners, by symbol, by time of day, per economic events, per variance from expected price and volumes, etc. This real time OLAP type of analytics is part of the new Big Data, which now can provide significant seeking alpha advantages.
Please explain what Tabb and Corvil refer to as ‘Speed2’ or ‘Meta-Speed’ (Sept 2016).
Also – why have increasing number of trading firms been addressing Speed2 opportunities for increase revenue?
Speed (or raw, pure speed which we can refer to as ‘Speed1’), is relative. There is no single speed that guarantees success. This is where ULL analytics can pay huge dividends, acting on data relating to speed; hence, aspects of speed must be continually measured.
Recent advances in technology and current and evolving market structures mandate that traders must view more nuanced aspects of speed. This brings us into a new era that Tabb and Corvil refer to as “Speed II,”. It revolves around meta-speed (information about speed). [4]
This pertains to understanding the dynamics, timeliness, measurability, auditability and transparency of speed and latency. Hence, the information around speed and latency is as important, if not more important, than speed itself. A critical aspect of Speed2 is deterministic latency.
What good is raw speed if firms do not understand whether the sell-side systems, exchanges, markets, and clients they are connecting to are fully functional? Or if a trading partner is in the beginning stages of failure, or in the process of being degraded?
A sell-side execution broker app is NOT fully functional if its T2T or order ack times exponential increase within few milliseconds following a Fed interest rate increase or Donald Trump tweet (because –for example – the execution broker erred weekend before in not setting NIC kernel bypass on, hence delaying ingress of bursty market data, following an upgrade). This is 1 example of many that can disrupt deterministic latencies and performance, and hence fill rates. However, technologies are available whereby a buy-side firm can learn of the order ack latency spikes in milliseconds, and immediately route to alternate sell-side execution brokers. *** This is where use of high speed memory Big Data analytics can provide a significant competitive advantage.
Many firms are developing internal business process management (BPM) benchmarks to fully understand the status of their own systems. A selection of those metrics increasingly should be provided to clients so they can better judge the trading ecosystem. This is good will among trading partners. But technology exists today where every trading client can, very precisely measure, analyze their trading ecosystem, and thus alert, and then alter real time trading apps, for competitive advantage.
Tabb and Corvil have stated that:
Today’s markets require microseconds and tomorrow’s will require nanoseconds
Why must market makers be keenly aware of ‘Meta-Speed’
Speed2 includes addressing decision points as to whether to send in an order or not. If the order is acting on an internal trading system market data latency pointing to high % or confidence of fill per most recent market data, then the firm will tend to send it, else hold off. This is most critical to market making firms, as they need to timely create markets to stay in business, let alone generate profits. Real time analytics are key to such trading decisions.
To trade and maintain market share, market makers not only need to connect with the largest exchanges, they increasingly need to link to the majority of, if not all, trading venues. Further, to manage adverse selection risk (the risk of being picked off), market makers need to be increasingly fast. This means buying direct market data feeds, exchange access, colocation services, and very fast intermarket connectivity.
How does a deterministic approach to low latency connectivity help create an optimal situation? How does this work and how is it accomplished?
An optimal situation includes a pertinent infrastructure, with application software and Linux kernels configured and tuned for deterministic latencies. This includes infrastructure configurations addressed earlier and software design principles to take advantage of multi threading, utilizing all available cores, with deep vector processing, thereby executing more instructions per CPU core clock cycle.[5]
To accomplish this successfully, 2 points are critical:
- ROI
Trading Firms vary in their Electronic Trading (ET) priorities, expertise, commitments, and expectations of ET impact to revenue and net income. Those that aspire to be leaders and successful (generate profits) in this space, especially must meticulously construct ROI projections for their proposed investments and commitments to be most competitive and increase market share.
To accomplish this, such firms must very extensively rely on Big Data analytics with metrics:
- Continuously extract stats of fill rates at low, median, peak 99% latencies.
- How about any fill rate stats over time?
- What is the fill% and revenue gain if T2T decreases by 100 micro seconds?
- What is the cost of infrastructure to accomplish this and to maintain it?
- What is the cost of not upgrading (loss of market share and revenue as competitors increase Speed1 (raw) and their use of Speed2.
Use these metrics to project capacity upgrades.
Machine Learning / Neural Networks (part of evolving Big Data evolution for ET) can project with significant confidence – what are multi variable factors that project latencies and fill rates, hence revenues. *** Again this is another excellent capability now available (and not too expensive) for Big Data analytics impacting the bottom line and major financial decisions.
Examples of firms A and B, opting for different strategies:
- Firm A ROI analytics point to very significant market share growth for very complex trading algo’s; hence they may opt to upgrade their market data infrastructure (and maybe even order flow) to a 100% pure FPGA based – for SIP and Level 2 feeds, with a vendor certified FPGA based normalization IP, and with a high speed interconnect (5 ns) forward market data to their proprietary algo trading system that combines FPGA’s for relatively simple algo’s and combo FPGA’s / Intel cores for more complex algos (Firm A has talented FPGA developers). AlgoLogic + Metamako provide such a solution.
- Firm B is smaller, with less expertise, projects modest market share improvements with lower market data latencies and overall deterministic T2T latencies. Their analytics points to modest expenditures and thus pursues a predominantly managed CoLo service with lower and more deterministic latencies. Another option may be a carefully configured/tuned vendor- distributed solution. An example: Thomson Reuters TREP
.
- Test, Profile, Analyze, Project
Trading Firms must utilize infrastructure architects/engineers and Developers, QA staff to determine what new infrastructures project to positive ROI, and then meticulously engineer, configure, profile tune, validate expected latencies, fill rates, and thus revenue (positive ROI)
In the end such metrics may play significant role as to whether a trading firm should stay in ET or exit the business. [6]
How can in-memory and other high performance databases and feed handlers support key functions like best execution, transaction cost analysis, market surveillance and algo back-testing?
Best Ex, TCA, and market surveillance can now be done much faster and comprehensively via Big Data Analytics / Machine Learning. This data includes historical and real – both structured and unstructured data. HPC and Exabyte in-mem databases, with high speed and more memory are available, along with more cores, GPU’s, FPGA’s, high speed interconnects to forward products of analytics – ex: TCA or alpha seeking event over high speed interconnect to alter a real time trading app
- FPGA based feed handlers with relevant data can accelerate the analytics
- Algo back-testing, with high speed memory will allow one more capabilities to test many variances and combinations of variables’ impacts on seeking alpha
- Products such as OneTick, can receive gamut of ‘reduced’ or ‘final’ data for correlation analytics, even machine learning, act on this historical and MAYBE real time data in memory and address all above areas.
- Speed of analytics, including generated events with a short-life of value, is increasingly important – especially in seeking alpha and in determining if sending in an order for execution has high probability of fill and profit.
Hence, the most deterministic latency market data, can be a major revenue maker, being input to TCA. OneTick can be a ULL subscriber of market data just as algo trading apps and thus have data ASAP for TCP analysis. For pure and deterministic speed, raw direct feeds, with Layer 1 switch market data fan-out will be optimal.
Timely and deterministic analytical historical and real time tick market data are required for TCA. To validate that TCA analytics will not impact ULL real time market data for trading apps and subscribers, offload the analytics then transmit alpha trading signals asynchronously via high speed interconnects and/or messaging middleware such as 60 East Technologies AMPS. The OneTick analytics and stream processing product can analyze and provide alpha alerts via their OneTick cloud offering, utilizing large and high speed memory.
Sell-side is forced to up the ante, offering expanded services to better understand and manage the trade lifecycle. Complex event processing (CEP) and tick data management are the consummate tools that can easily be recast, molded to unearth trade performance, a goal that is central in the investment process as liquidity continues to be fragmented and fleeting. Now uncovering the performance of trading behavior through customized, personalized transaction cost analysis is a critical component to any investors’ profitability.
Real-time TCA provides traders with information on costs, quality and potential market impact as it happens, where analytics become actionable information at the point of trade. Determining these metrics on an internalized basis offers the ability to adjust an algorithm’s behaviour in real time. Execution strategies and routing logic can be adjusted intelligently in response to outlier conditions; either aggressively or passively in reaction to market conditions or broker behaviour.
In Sum:
Measure TCA results in real time as you’re trading and make adjustments and changes accordingly
Players in real time TCA:
OneTick (MAYBE BE POSSIBLE if not now maybe soon)
- Built-in high precision analytical library for TCA analytics and market price benchmarks
- Disparate data is normalized and cleansed (Deals, Quotes, Books, Orders, Executions)
- Real-time stream processing engine, historical time-series database and visual dashboards
- Flexible choices for building analytical models for execution/broker performance, market impact, etc
TabbMetrics Clarity Tool
As partners with TabbMetrics – Bloomberg, Cowen, Sanford Bernstein, Weeden
Pragma
Instinet
How do functions such as execution, transaction cost analysis (TCA), market surveillance & algo back testing impact market data system latency?
Any market data for transaction cost analysis, market surveillance & algo back testing must NOT impact T2T or order ack times or trade execution times. Offload any analytics and above functions asynchronously to T2T real time order flow. Proper software can replay market data with multiple algo’s at original rates, latencies, or alter (ex: speed-up, change dynamics, algo goals, etc)
Execution
For order execution, T2T and order ack times are critical performance metrics; hence, market data infrastructures are optimized for speed and deterministic latencies.
TCA
From Tabb:
TCA is increasingly being used in real time. TCA can therefore generate alpha by projecting and exposing lower costs and specific trading venues for buying or selling securities. This is referred to as “opportunity cost” and is very time sensitive. The first trading firm(s) to identify this (may be micro, not milliseconds) stands to benefit. This is another example of ‘Speed2’.
Hence, the most deterministic latency market data, can be a major revenue maker, being input to TCA.
Market surveillance
For the same reasons as TCA, add order flow data, and realize that fast and more deterministic market data will speed up Market surveillance, post trade and compliance.
Algo Back Testing
Note speed up mentioned for TCA and understand that a Tick DB will have all data for algo back testing replays.
How can high-performance technologies like hardware acceleration and in-memory databases improve trade executions and TCA ?
Also – are these ‘apples & oranges’? Are both capabilities or technologies needed for higher performance in market data management?
Both are required as hardware acceleration will speed up (and deterministically) market data to high speed memory regions for analytics that may include timely alpha seeking strategies.
Are best practices for accessing high-speed market information widely agreed upon? Are they much the same across all types of firms? Do they change according to specialization/function/size?
Are they agreed upon- NO. Some feel few milliseconds latencies for market data still suffices. Others strive for nanoseconds. Key is to ID your business goals and ROI on speed up spending. Specialization and function are significant factors. Goals of Prop Traders, Market Makers, HFT traders, arbitrage, are much more latency sensitive than most Buy side and asset managers.
Have they changed in the past two years? How will the change over the next two years?
Last 2 years:
- Already mentioned: impact of what Tabb/Corvil refer to as Speed2, thus taking advantage of recent advances in Big Data analytics (infrastructure and methodology such as Machine Learning) for acting on market data and all aspects of T2T.
- Layer 1 switches, with no need for packet examination +FPGA for speed, are now part of ULL CoLo market data fan-outs in 5 ns, significantly contributing to decrease in latencies.
- Big Buffer switches to hold (not drop) spikes in real time data for Big Data analytics. While such switches are not ideal for market data or order flow T2T latencies, they are an excellent choice for ULL Big data analytics which can quickly forward alpha seeking trade signals over a high speed interconnect to a real time trading app.
- Very significant enhancements in FPGA processing, significantly lowering T2T latencies. 2016 marked a year where some simple AlgoTrade apps may be 100% fully FPGA with T2T in approximately 1 microseconds. One can now develop Order Book builds and FIX engines on FPGA based NICs.
- Raw Speed continues to increase:
- Per STAC event Nov 7, 2016 – NYC – One participant noted Industry leadingTick-2-Trade latencies have decreased by factor of 10 every 3 years. I recalled where I was in each time period and what were leading technologies for the lowest ET technologies and find these accurate -as I always tracked the competition, and worked to beat the competition!
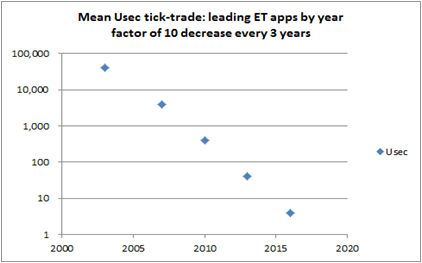
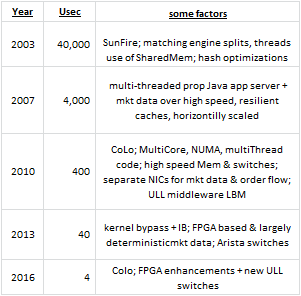
My chart above that I created per attendance at Nov 7 STAC event in NYC
Some factors (totally my creation):
- Key point to this is that the proportion of “ULL” trading continues to increase; hence this would leave one to project that trading firms that choose not to “speed up” or engineer more deterministic latencies, will decrease their market share.
- More firms are categorizing news sentiment analytics as “market data” and receiving feeds from vendors of these analytics, which are now part of more complex but possibly more reliable trade recommendations (up to the firm to take advantage of this). Key vendors – RavenPack. Thomson Reuters, Bloomberg
- Real Time Big Data (Machine Learning), some in Cloud, now send more time sensitive alpha trading signals over high speed interconnects to Trading Apps
- Kernel Bypass is now ubiquitous; I/O’s are at approx. 1 uSec, down from 12 uSecs
- Increased use of FPGA based kernel bypass to sub uSec I/O latencies
- GPU’s remain important speed factor but more for risk (ex MonteCarlo) and analytics
FUTURE
- Intel’s synergies per Altera acquisition may result in further lower and deterministic latencies for all aspects of ET, including market data, algo trade design, risk analytics, TCA, and order flow.
- Ability to more easily program in FPGA:
- New libraries from Intel, along with a C like language ‘A++’, may supplement OpenCL for increases in programming complex trading algos in FPGA
- High Speed interconnects such as Intel’s Omni Path Architecture (OPA) may be faster and more deterministic than InfiniBand (IB), due to no need for a bus adapter and IB’s requirement to fill a buffer before sending
- Binary FIX Protocol
REFERENCE
Link below lists virtually all expertise I have in ULL Electronic Trading(ET) architectures. I will teach an ULL ET course at NYU Summer 2017.
also – was Dec 8, 2016 Panelist for A-Team Webinar re: perspectives on strategic ULL market data architectures & how trading firms can realize ROI, seek alpha, expand market share, address risks, compliance. Access webinar recording here:http://bit.ly/2fXujEo.
[3] https://access.redhat.com/sites/default/files/attachments/201501-perf-brief-low-latency-tuning-rhel7-v1.1.pdf
[4] http://tabbforum.com/opinions/rethinking-speed-in-financial-markets-part-3-the-speed-rule?print_preview=true&single=true
[5] http://tabbforum.com/opinions/redefining-and-reimagining-speed-in-the-capital-markets?ticket=ST-14852041740069-qgIDZjoi2HWsc6MNhDsNrNzvNIlTfGDkJWUQjb1b
[6] http://tabbforum.com/opinions/welcome-to-the-jungle-understanding-speed-in-the-capital-markets

